

همانطور که می دانید فایل Robots.txt به خزندگان (یا همان کراولرهای) موتورهای جستجو و سایر کراولرها می گوید کدام صفحه از سایت برای اسکن کردن باز است و کدام صفحه را نمیتوانند بررسی کنند. این فایل امروزه توسط بیشتر سایت ها مورد استفاده قرار می گیرد و بیشتر کراولرهای وب به آن احترام می گذارند. این پروتکل اغلب بر روی سایت هایی استفاده می شود که در حال توسعه هستند یا بر روی صفحاتی مورد استفاده قرار می گیرد که دوست ندارند در اختیار عموم باشند. در فرآیند بهینه سازی سایت برای موتورهای جستجو یا همان سئو ، فایل Robots.txt نقش مهمی در بهینه سازی خزش و ایندکس موتورهای جستجو بازی می کند.
تاریخچه فایل Robots.txt
پروتکل Robots.txt در اصل توسط یکی از پیشگامان فضای اینترنت و تولید کننده Allweb یعنی Martijn Koster پیشنهاد شد. او در اوایل سال 1994 این پیشنهاد را داد که در این زمان برای شرکت Nexor کار می کرد. نویسنده انگلیسی به نام Charlie Stross ادعا می کند این پیشنهاد را زمانی که او خزنده بدخواهی را ایجاد کرد که باعث بروز مشکلاتی بر روی سرورها شد به Koster داد. به لطف سادگی و مفید بودن این پروتکل، بیشتر سایت ها و موتورهای جستجوی اولیه نیز خود را با این فایل سازگار کردند. تا به امروز، موتورهای جستجویی همچون گوگل، بینگ، یاهو و سایر موتورهای جستجو به این پروتکل احترام می گذارند و خود را از صفحاتی که توسط کاربر محدود شده است دور نگه میدارند.
برای فرایند سئوی سایت نیز فایل robots.txt به بخش یکپارچه فرایند بهینه سازی تبدیل شده است. زیرا جامعه آگاهی بیشتری در مورد مفاهیمی همچون جریان تساوی لینک و بودجه خزش به دست آورده اند. امروزه سئوکاران متخصص و با تجربه بر روی این پروتکل تکیه می کنند تا بتوانند ربات ها را از خرش صفحات پویا، صفحات مختص ادمین، صفحات پرداخت و سایر اسناد مشابه باز دارند. با اینحال همه خزندگان از این استاندارد پیروی نمی کنند. ربات های اسپم، کپی کنندگان محتوا، نرم افزاری های هک و بدخواه همگی دستورالعمل های موجود در این فایل را نادیده می گیرند.
در برخی از موارد، خزندگان بدخواه حتی خزش این صفحات را در اولویت کاری خود قرار می دهند. سایت های آرشیوی همچون Archive Team و Internet Archive چنین استانداردهایی را نادیده می گیرند و آن را به عنوان یک پروتکل منسوخ می شناسند که بیشتر برای موتورهای جستجو ایجاد شده است. گروه های آرشیوی معمولا ادعا می کنند اطلاعاتی را ذخیره می سازند که تکامل اینترنت و سایر بنیانگذاران را مانیتور می کند.
کاربرد فایل Robots.txt
فایل robots.txt معمولا در دایرکتوری روت سایت آپلود می شود. بیشتر ربات ها به گونه ای برنامه ریزی شده اند که به دنبال آدرسی همچون www.example.com/robots.txt می گردند. برای بیشتر ربات ها، پیدا نکردن یک فایل robots.txt معتبر در این موقعیت بدین معنی است که همه صفحات موجود در سایت برای خزش آزاد است. این موضوع حتی زمانی که فایل در موقعیت و آدرس دیگری نیز آپلود شده باشد صدق می کند. ایجاد فایل robots.txt به سادگی نوشتن دستورالعمل بر روی نوت پد و ذخیره کردن آن با فرمت txt و با نام robots است.
بعد از اینکه فایل robots.txt را ایجاد کردید باید آن را از طریق FTP یا cPanel (یا هر برنامه مدیریت هاست و سروری) به دایرکتوری روت دامنه آپلود کنید. بیشتر پلتفرم های مدرن مدیریت محتوا و افزونه های سئو این فایل را به صورت خودکار ایجاد می کنند. بنابراین شما می توانید وارد آن شوید و ویرایش های مورد نیاز را اعمال نمایید. مواردی که در ادامه بیان میشود رایج ترین کاربرد فایل های robots.txt است.
- جلوگیری و رد ایندکس کردن: در میان تمامی دلایلی که برای استفاده از فایل robots.txt بیان می شود، این مورد یکی از رایج ترین هاست. وبمسترها معمولا دوست دارند جلوی ایندکس و خزش صفحاتی که به تجربه های جستجوکنندگان مرتبط نیست را بگیرند. به عنوان مثال صفحاتی همچون بخشهای در حال ساخت، نتایج جستجوی داخلی، محتوای تولید شده توسط کاربر، پی دی اف ها، صفحات تولید شده توسط فیلترها و …
- حفظ بودجه خزش: وب سایت های بزرگی که هزاران صفحه در خود دارند معمولا دوست ندارند همه صفحاتشان به هنگام بازدید ربات های گوگل مورد خزش قرار بگیرد. آن ها این کار را برای افزایش شانس خزش صفحات مهم و ایندکس آن ها انجام می دهند.
خزش منظم و مکرر بر روی صفحات فرود ترافیک طبیعی بدین معنی است که بهینه سازی اعمالی شما به زودی بر روی صفحه نتایج موتورهای جستجو نشان داده خواهد شد. این موضوع همچنین بدین معناست که صفحاتی که لینک شده اند می توانند از انتقال لینک بیشتر نفع ببرند.
- بهینه سازی جریان تساوی لینک ها: فایل txt در بهینه سازی جریان تساوی لینک ها برای صفحات سایت می تواند مفید باشد. با دور نگه داشتن خزندگان از صفحاتی که اهمیت زیادی ندارند، تساوی لینک های داخلی در صفحات فرود ترافیک طبیعی حفظ میشود. این موضوع بدین معنی است که قدرت رتبه بندی سایت شما بر روی صفحاتی که اهمیت زیادی دارد تمرکز می کند و همین امر باعث می شود این صفحات در نتایج جستجو رتبه بالاتری کسب نماید و ترافیک طبیعی بیشتری به خود جذب کند.
- فهرست نقشه سایت: فایل robots.txt را می توان برای این منظور نیز به کار برد. در این شرایط فایل robots.txt به موتورهای جستجو می گوید که در چه مکانی میتوانند نقشه سایت را پیدا کنند. این موضوع اختیاری است زیرا می توان نقشه سایت را از طریق کنسول جستجوی گوگل نیز ثبت کرد و همین نتیجه را گرفت اما استفاده از این فایل برای ثبت نقشه سایت، ضرری نخواهد داشت.
- امنیت: برخی از صفحات نباید در اختیار عموم قرار بگیرند. صفحات لاگین و صفحات ادمین از این نمونه صفحات است. هر چقدر این صفحات امن تر باشند خطر حمله به سایت نیز کاهش پیدا می کند. (البته با ثبت این صفحات در فایل روبات دات تکست افراد میتوانند با مشاهده این فایل، آنها را ببینند!)
- تعیین تاخیر خزش: وبسایت های بزرگی همچون سایت های تجارت الکترونیک و ویکی ها اغلب به صورت دسته ای محتوای خود را منتشر میکنند. در چنین شرایطی ربات ها به سرعت وارد کار می شوند و تلاش می کنند کل محتوای منتشر شده را یکجا اسکن کنند. این موضوع باعث ایجاد فشار بر روی سرور می شود و در نهایت سرعت بارگذاری سایت کم می شود یا Downtime ای ایجاد می گردد. چنین سایت هایی می توانند با نوشتن دستورالعمل های موجود در فایل txt از بروز چنین شرایطی خودداری کنند. در این وضعیت، صفحات جدید به تدریج خزیده می شود و فرصت کافی به سرور داده می شود.
نوشتن و فرمت بندی فایل robots.txt
این فایل زبان ساده و پایه ای دارد که حتی افرادی که برنامه نویسی بلد نیستند می توانند در زمان بسیار کوتاهی نوشتن آن را یاد بگیرند. این کار اغلب شامل تعیین صفحاتی است که خزندگان نباید به آن دسترسی داشته باشند. این ها واژه های عمومی هستند که باید در نوشتن فایل robots.txt کاربردی مدنظر داشته باشید:
- User-agent: این کد نام خزنده ای که می خواهید خطاب قرار دهید را مشخص می کند. این قسمت می تواند Googlebot برای خزندگان طبیعی گوگل، Bingbot برای خزندگان بینگ ، Rogerbot برای خزندگان MOZ و غیره باشد. کاراکتر * را می توان برای هدف قرار دادن تمامی خزندگان مورد استفاده قرار داد.
- Disallow: این دستورالعمل توسط مسیر دایرکتوری همچون /category دنبال می شود تا به ربات ها بگوید لازم نیست هر آدرسی که در این بخش وجود دارد را بخزند. آدرس های تکی همچون category/sample-page.html را می توان به کمک همین کد از دسترس ربات ها دور نگه داشت.
- Crawl-delay: این کد به ربات ها می گوید که تاخیر خزش چند میلی ثانیه باید باشد. مقدار این قسمت اغلب بسته به اندازه سایت و ظرفیت سرورهای آن تغییر پیدا می کند.
- Sitemap: این بخش موقعیت نقشه سایت را نشان می دهد.
فرض کنید شما ادمین یک سایت وردپرسی هستید و می خواهید مطمئن شوید که برخی از صفحات و صفحات پویا هرگز در نتایج موتورهای جستجو نشان داده نخواهد شد. فایل robots.txt شما ممکن است چنین باشد:

خط اول به خاطر کاراکتر * که در خود دارد همه خزندگان را خطاب قرار می دهد. این در حالیست که خط دوم مشخص می کند که همه صفحاتی با آدرسی که شامل /wp-admin هستند نباید خزیده شوند. خط سوم، به ربات ها می گوید که همه صفحاتی با علامت سوال نباید ایندکس شوند. علامت سوال و نشانه های معادل کاراکترهایی هستند که در آدرس های پویا دیده می شوند. توجه داشته باشید که لازم نیست دامنه روت را به هنگام مشخص کردن صفحات و دایرکتوری هایی که می خواهید مسدود کنید، در این فایل بگنجانید. Slug آدرس یا مسیر فایل کافی است.
بهترین تمرینات و نکات
تمرینات متعددی وجود دارد که شما را مطمئن می سازد پیکربندی فایل robots.txt به درستی انجام شده و می تواند علاوه بر تجربه کاربری خوب، تاثیر مثبتی بر روی فرآیند سئو بگذارد. در ادامه برخی از تمرینات مهم را با هم مرور می کنیم:
- هرگز فایل txt را جایی به جز دایرکتوری روت آپلود نکنید. نباید نام آن را تغییر دهید. اگر ربات های جستجو نتوانند آن را در مسیر www.example.com/robots.txt پیدا کنند، قادر نخواهند بود آن را بیابند و همین امر باعث می شود فرض کنند که همه صفحات موجود در سایت برای خزش آزاد است.
- نام فایل به حروف کوچک و بزرگ حساس است. بیشتر خزندگان فایلی که با نام robots.txt ایجاد شده است را متفاوت از فایلی با نام robos.Txt می دانند. مطمئن شوید که نام فایل را با حروف کوچک نوشته اید.
- همانطور که قبلا نیز بیان کردیم، خزندگان بدخواه برخی از اوقات خزش آدرس هایی که در این فایل مسدود شده است را در اولویت قرار می دهند تا بتوانند نقطه ورودی به سایت بیابند. برای مقاصد امنیتی میتوانید از تگ متای noindex به جای این فایل برای پیشگیری از ایندکس چنین صفحاتی استفاده کنید.
- در برخی از موارد، وبمسترها دستورالعمل های disallow را به گونه ای می نویسند که به طور غیر عمد مانع از دسترسی ربات ها به فایل های CSS و جاوا اسکریپت می شود. این عناصر برای ایندکس بهینه سایت باید خزیده شده و ایندکس گردند. زمانی که کل دایرکتوری را با این فایل مسدود می کنید باید اطمینان داشته باشید که این فایل ها برای ربات های جستجو قابل دسترس است.
- صفحاتی که از ربات های جستجو دور نگه داشته شده باشند تساوی لینک را به صفحات داخلی و خارجی که به آنها لینک داده اند منتقل نمیکنند. اگر می خواهید صفحه ای را ایندکس نکنید اما می خواهید تساوی لینک را انتقال دهید از تگ متای noindex, follow استفاده کنید.
- زیر دامنه ها در بیشتر موتورهای جستجو به عنوان سایت متفاوتی در نظر گرفته می شوند. این موضوع بدین معنی است که فایل txt در دامنه روت در این زیر دامنه ها دنبال نخواهد شد. در حقیقت g-ads.org باید فایل robots.txt متفاوت تری از زیر دامنه اش مثلا seotools.g-ads.org داشته باشد.
شما می توانید از طریق ابزار robots.txt tester کنسول جستجوی گوگل، سلامت فایل خود را بسنجید. کافیست به این سایت بروید و به کمک این ابزار فایل Robot.txt خود را بررسی نمایید. اگر فایل درست کار کند، چیزی شبیه شکل زیر خواهید داشت:
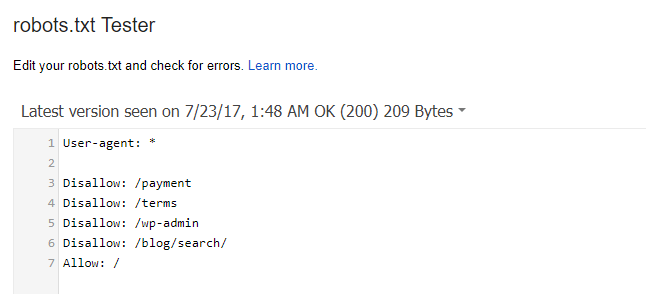
برای ایجاد این فایل میتوانید از ابزار آنلاین سازنده فایل robots.txt جی ادز استفاده کنید.
















سلام اقای قبیله
مقالاتتون واقعا مفید هستن ممنون از زحمات شما و سایت پربار جی ادز
سلام خسته نباشید. مفید بود ممنون.
من یک وبلاگ دامنه دار دارم (با وردپرس نیست). خواستم بدونم این فایل رو باید کجای وبلاگم قرار بدم؟ قبلا خود وبلاگم این فایل رو داشت اما همه چیز disallow بود. حالا که ویرایشش کردم نمیدونم کجا باید فایل جدید رو قرار بدم.
خیلی خیلی ممنون میشم اگر راهنمایی کنین.
سلام.
معمولا داخل سرویسهای تبلیغاتی دسترسی به این فایل ممکن نیست. میتونین از تگ noindex داخل صفحاتی که نمیخواین ایندکس بشن استفاده کنین.
سلام
به نظرتون منطقی هست کدهای زیر به فایل robots.txt افزوده بشه؟
Disallow: /comments/
Disallow: */comments/
سلام. توصیه نمیکنم این کار رو انجام بدین.
تشکر بابت پاسخگویی
نظرتون در مورد سه مورد زیر چی هست ؟
Disallow: /feed/
Disallow: */feed/
Disallow: /comments/feed
سلام
با استفاده از این کد “هک کردن” هم ممکنه؟
من وب دارم و هربار که رمزمو عوض میکنم یکی میاد این کد رو به وبم میده
User-agent: *
Disallow: /process/
Sitemap: آدرس وبم/sitemap.xml
میترسم هک شده باشم
سلام دوست عزیز، بهتر است این موضوع را با شرکت های پشتیبانی و فنی مطرح نمائید.