
در قسمت قبلی این سری آموزشها به بررسی متریکهای پیشبینی کننده و پردیکتیو آئودینس میپردازیم.
در این قسمت از سری آموزشهای جی ای 4 کریستا سیدن به همراه کانی ترین مدیر محصول گوگل، توضیحاتی در رابطه با مدلسازی کانورژن در پراپرتیهای جی ای 4 را در اختیار ما قرار میدهند.
مدلسازی کانورژن چیست؟
برخی اوقات در پروسه اندازهگیری کانورژن شرایطی به وجود میآید که در آن کانورژنها به دلایل مختلفی همچون محدودیتهای مرورگر و یا یک سری قوانین حفظ امنیت کاربر نمیتوانند ارتباط خود با کانالهای بازاریابی که از آنها آمدهاند را حفظ کنند. در چنین شرایطی کارشناسان دیجیتال مارکتینگ نمیتوانند تشخیص دهند که کانالهای بازاریابی مدنظر آنها تأثیرگذار بودهاند یا نه. در این حالت کاربران با استفاده از تکنیک مدلسازی کانورژن میتوانند دیتاهای جدیدی ایجاد کرده تا بهتر بتوانند رفتار کاربران در سایت و یا اپلیکیشن خود را رصد کنند.
مدلسازی کانورژن از فناوری هوش مصنوعی استفاده میکند تا ایرادات کانورژنهای مختلف را پیدا کرده تا نهایتاً بتواند مدل جدیدی از آنها را بسازد.
مدلهای ساخته شده در این تکنیک، اتصالی بین کانورژنهای ایونتهای مختلفی همچون purchase و یا دانلود با کانالهای متفاوتی مثل فروش مستقیم و یا ترافیک ارگانیک را برقرار کرده تا کاربران دیتاهای کاملی برای بررسی رفتار بازدیدکنندگان سایت و یا اپ خود داشته باشند.
بدین ترتیب با استفاده از مدلسازی کانورژن ما دیگر نگران تشخیص کانالهای بازاریابی مؤثر نبوده و میتوانیم از گزارشهای دقیقتر برای بررسی رفتار کاربران استفاده کنیم.
چرا مدلسازی کانورژن مهم است؟
مدلسازی کانورژن از اهمیت بالایی برخوردار است و دلایل ما برای این ادعا نیز این 2 مورد میباشند:
- به طور طبیعی کانورژنها در طول زمان میتوانند به دلایل مختلفی اتصال خود با کانالهای بازاریابی که از آن آمدهاند را از دست دهند. این موضوع بدان معناست که در طول زمان دیتاها میتوانند تحت دلایل مختلفی از بین بروند. در چنین شرایطی ما باید از مدلسازی کانورژن استفاده کنیم تا دیتاهای جدید ساخته تا بتوانیم از آنها در گزارشهای خود استفاده کنیم.
- همانطور که پیشتر نیز به آن اشاره کردیم؛ یک سری از قوانین حفظ حریم خصوصی کاربران وجود دارند که اجازه اندازهگیری کامل برخی از کانورژنها را نمیدهند. بنابراین در این بخش نیز ما به مدلسازی کانورژن نیاز داریم تا بتوانیم دیتاهای خود را کامل کرده و از آنها برای بررسی رفتار کاربران استفاده کنیم.
مدلسازی کانورژن چگونه انجام میشود؟
برای ساخت مدلهای جدید از کانورژنها ما از منابع دادههای قابل مشاهده که توانستهاند ترافیک مناسبی دریافت کنند استفاده میکنیم. به همین منظور سیگنال های مختلفی را مورد بررسی قرار میدهیم که برای ساخت مدلهای جدید کانورژن به آنها نیاز داریم. برخی از سیگنالهایی که برای مدلسازی از آنها استفاده میکنیم به شرح زیر میباشند:
- Device type: این سیگنال به دستگاههای مختلف دسکتاپ، تبلت و موبایل تقسیم میشود.
- Conversion type: این سیگنال مربوط به ایونتهای مختلفی همچون ایونتهای خرید، دانلود و یا اضافه کردن به سبد خرید میشود که کیفیت مناسبی از دادهها را دارند.
- Country: کشورهایی که کاربران از آنها از سایت یا اپ ما بازدید کردهاند نیز میتواند به عنوان یک سیگنال برای مدلسازی کانورژن در نظر گرفته شوند.
- Browser type: مرورگرهای مختلفی مثل کروم، سافاری، فایرفاکس و یا سایر مرورگرهای معتبر میتواند به عنوان منابع دادههای مناسبی برای ساخت مدلهای جدید در نظر گرفته شوند.
تکنیک holdback validation
در پروسه مدلسازی کانورژن حفظ کیفیت دادهها از اهمیت بالایی برای ما برخوردار میباشد؛ چراکه تنها در صورت داشتن دیتاهای باکیفیت ما میتوانیم گزارشهای دقیقی از نحوه رفتار کاربران در سایت و یا اپ خود داشته باشیم. استفاده از تکنیک holdback validation یکی از روشهایی است که با آن میتوانیم دیتاهای باکیفیتی در مدلسازی کانورژن داشته باشیم.
در این تکنیک اگر ما یک منبع دیتای اولیه داشته باشیم؛ بخشی از آن را جدا کرده و مدلسازی کانورژن را برای آن بخش انجام میدهیم. در نهایت مقایسه مدل ساخته شده با نمونه اولیه دیتا این امکان را برای ما فراهم میکند تا هرگونه تغییر در دیتاها را تشخیص دهیم. در این تکنیک ما از فناوری هوش مصنوعی استفاده میکنیم تا کیفیت دیتاهای ساخته شده خود را بالا ببریم.
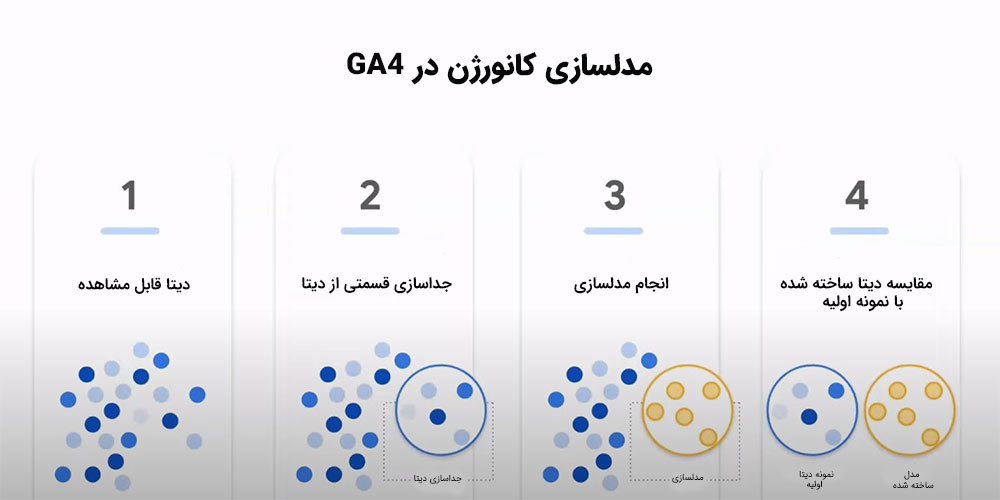
توجه داشته باشید که تمام این پروسه با استفاده از منابع دیتاهای اولیه ما صورت میگیرد. بنابراین هر چه دیتاهای وردی ما قویتر بوده و کیفیت بالاتری داشته باشند؛ مدلهای ساخته شده نیز دقیقتر خواهند بود.
مدلسازی کانورژن تکنیک کاربردی میباشد که در صورت از بین رفتن قسمتی از دیتا کاربرد داشته و به ما کمک میکند تا درک عمیقتری از دیتاهای کاربران خود داشته باشیم.















